The ability to reuse collected data and transfer trained policies between robots could alleviate the burden of additional data collection and training. While existing approaches such as pretraining plus finetuning and co-training show promise, they do not generalize to robots unseen in training.
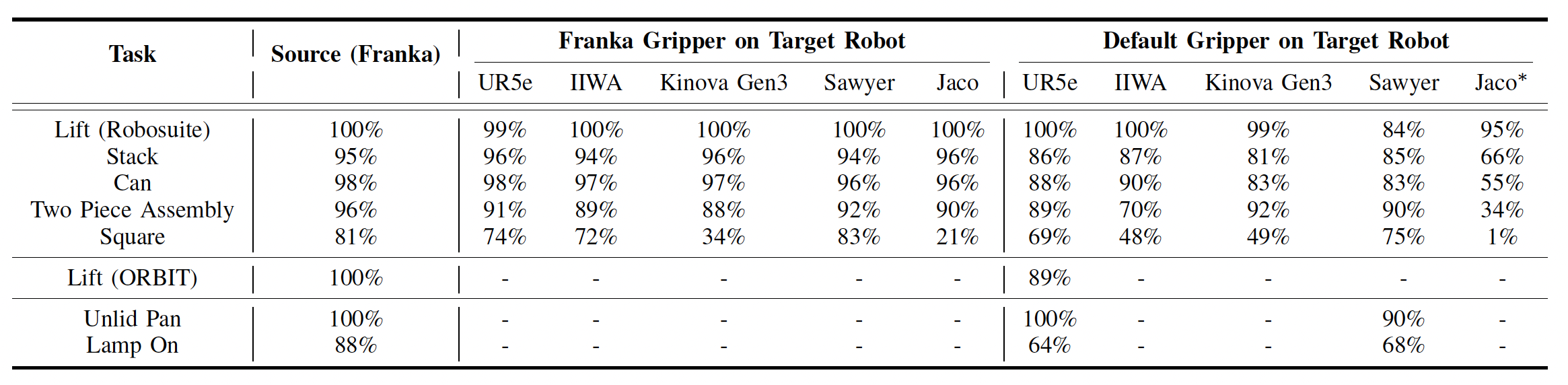
Focusing on common robot arms with similar workspaces and 2-jaw grippers, we investigate the feasibility of zero-shot transfer. Through simulation studies on 8 manipulation tasks, we find that state-based Cartesian control policies can successfully zero-shot transfer to a target robot after accounting for forward dynamics.
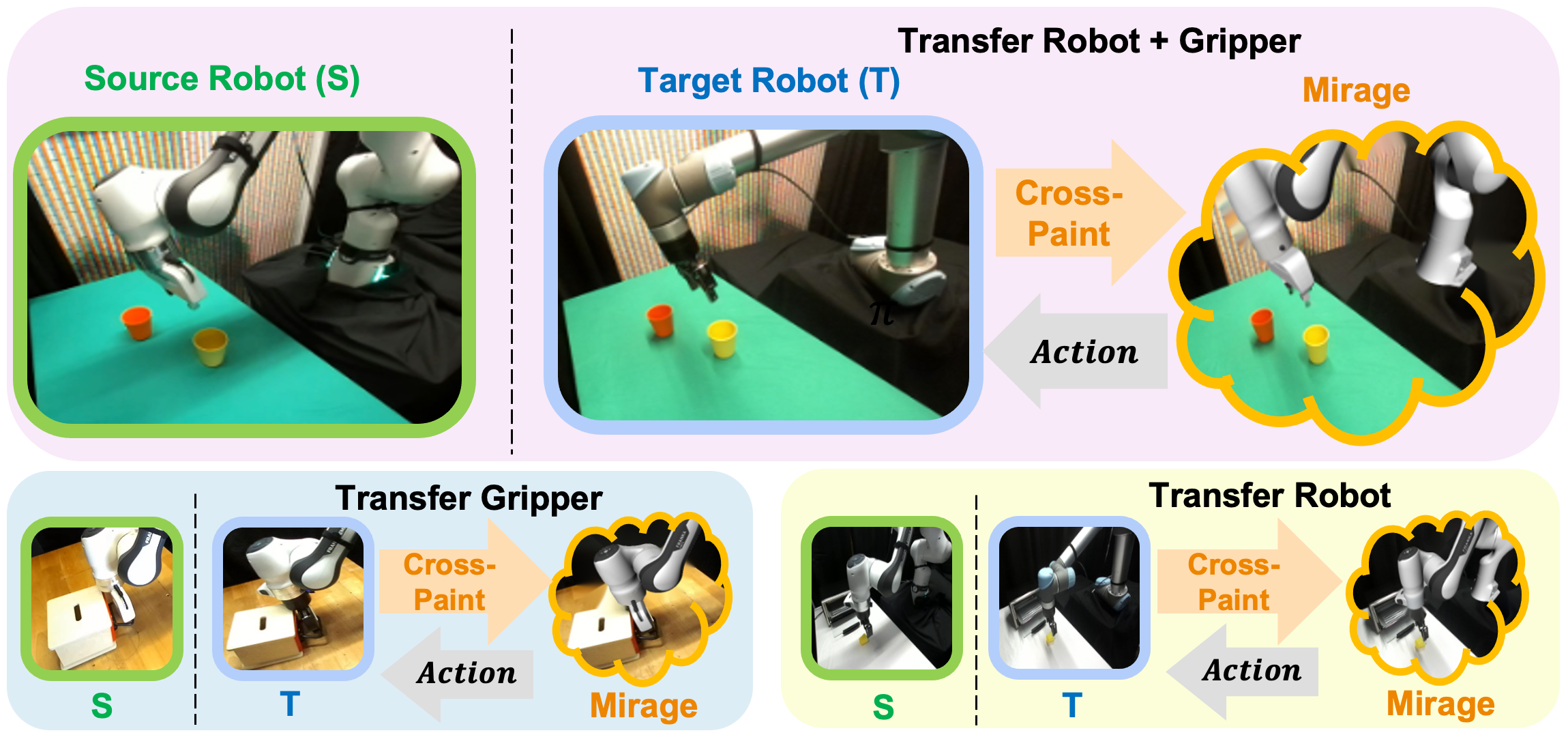
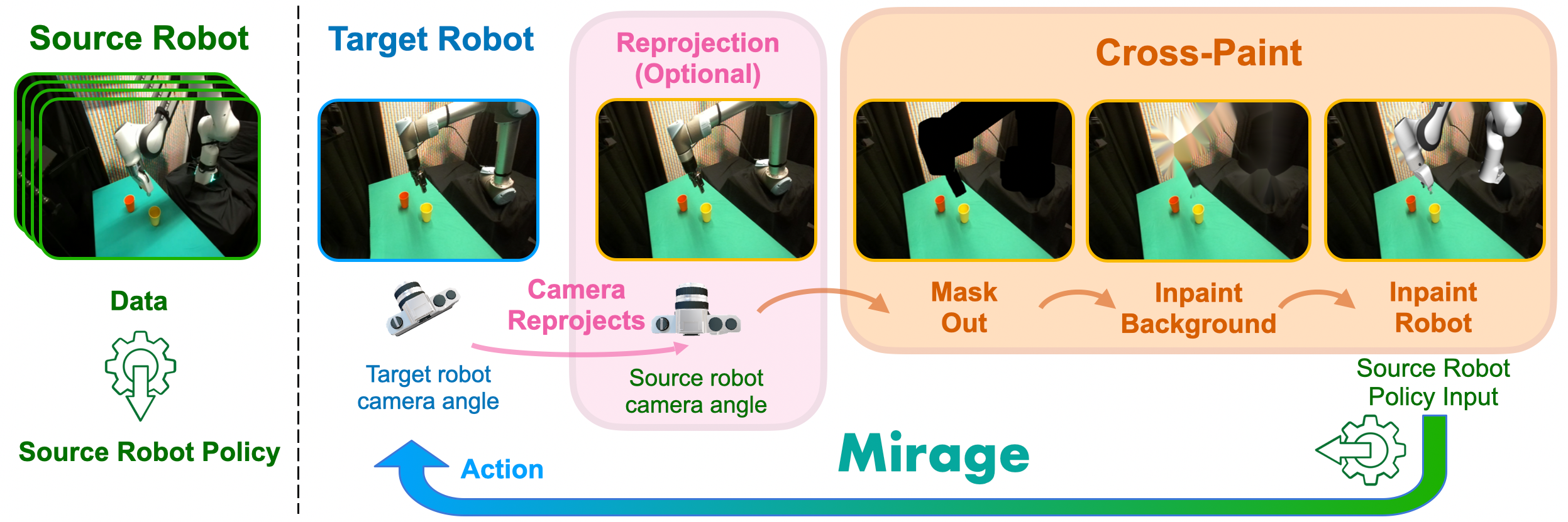
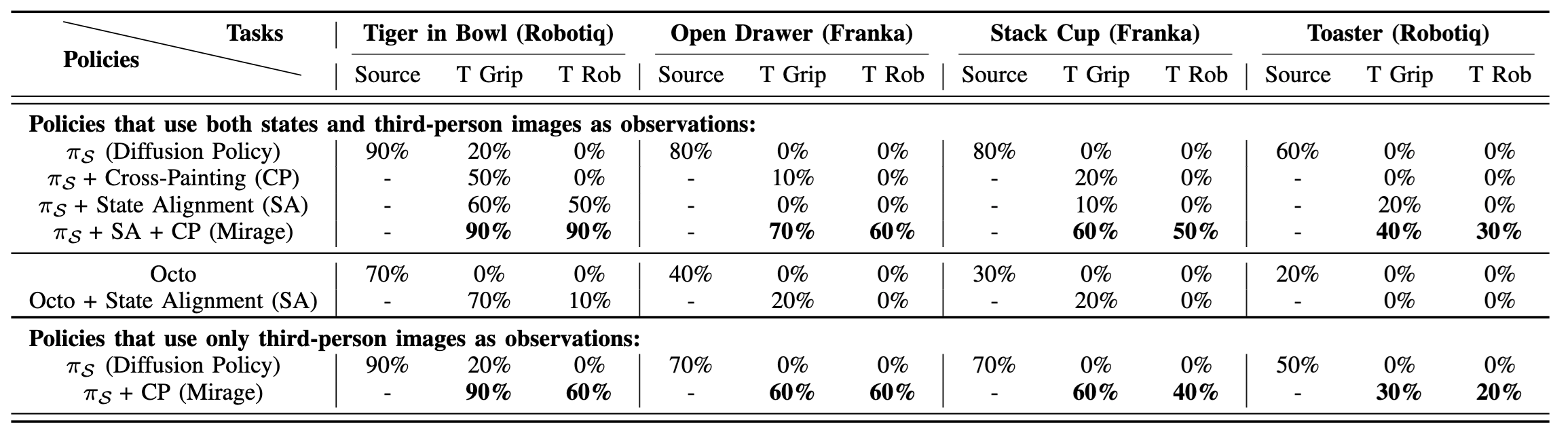
To address robot visual disparities for vision-based policies, we introduce Mirage, which uses “cross-painting”—-masking out the unseen target robot and inpainting the seen source robot—-during execution in real time so that it appears to the policy as if the trained source robot were performing the task. Mirage applies to both first-person and third-person camera views and policies that take in both states and images as inputs or only images as inputs. Despite its simplicity, our extensive simulation and physical experiments provide strong evidence that Mirage can successfully zero-shot transfer between different robot arms and grippers with only minimal performance degradation on a variety of manipulation tasks such as picking, stacking, and assembly, significantly outperforming a generalist policy.